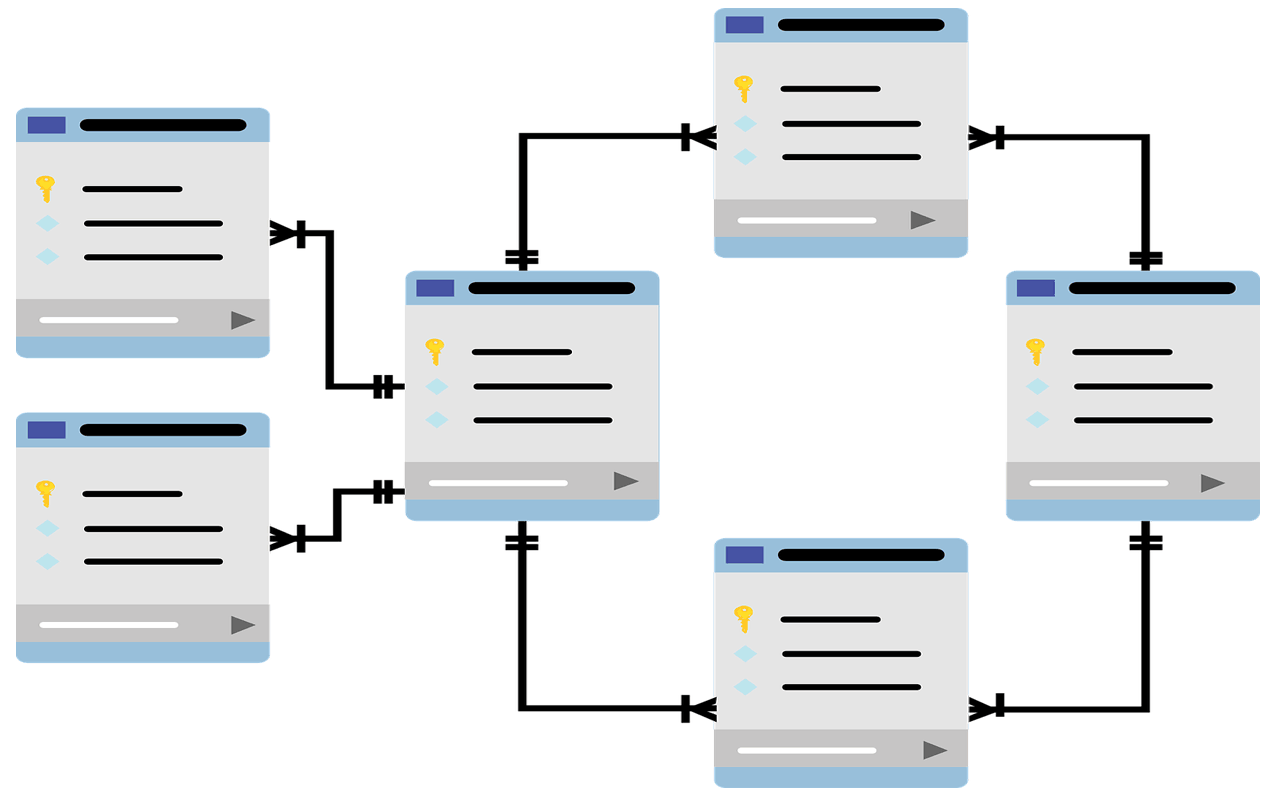
Base de données relationnelle
Une base de données est un système organisé permettant de stocker, gérer et interroger des informations de manière efficace. Elle permet de conserver de grandes quantités de données structurées et d'y accéder rapidement.
Une base de données relationnelle est un type particulier de base de données où les informations sont organisées en tables, et où les relations entre les données sont définies via des clés.

{kind=link}
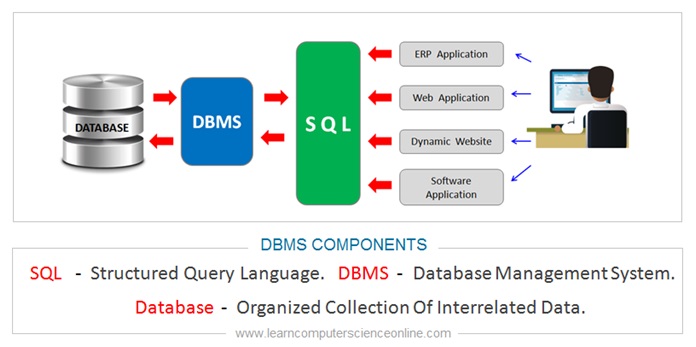
Les Systèmes de Gestion de Bases de Données (SGBD), ou DBMS (Database Management System), sont les logiciels permettant de créer, administrer et interroger ces bases.
Les plus utilisés sont :
- MySQL
- PostgreSQL
- MariaDB
- SQL Server
- Oracle
La quasi-totalité des SGBD relationnels utilisent un langage standardisé : SQL (Structured Query Language).

{kind=link}
Modèle relationnel
Le modèle relationnel, proposé par Edgar F. Codd en 1970, organise les données sous forme de tables (relations). C'est aujourd'hui le modèle dominant des bases relationnelles.
Table (Relation) : Une table représente un concept ou une entité (ex. : clients, produits, commandes).
Enregistrement (Tuple) : Chaque ligne d'une table représente un enregistrement unique.
Attribut (Champ / Colonne) : Chaque colonne décrit une caractéristique de l'entité.

{kind=link}
Clés
Les clés sont essentielles pour l'organisation et la fiabilité des données. Elles permettent d'identifier distinctement les enregistrements et de créer des relations entre les tables.
Clé primaire (Primary Key)
- Identifie de manière unique chaque ligne d'une table.
- Doit être unique et non nulle.
- Est souvent un entier auto-incrémenté (
AUTO_INCREMENT).
Clé étrangère (Foreign Key)
- Fait référence à la clé primaire d'une autre table.
- Etablit une relation logique entre deux tables.
- Garantit l'intégrité référentielle.
Clé candidate (Candidate Key)
- Toute colonne (ou combinaison de colonnes) pouvant servir de clé primaire.
- Doit être unique et non nulle.
- Une table peut avoir plusieurs clés candidates, mais une seule est choisie comme clé primaire.
Clé composite (Composite Key)
- Une clé primaire composée de plusieurs colonnes.
- Utilisée lorsque aucune colonne seule ne peut identifier un enregistrement.
Clé unique (Unique Key)
- Garantit l'unicité des valeurs d'une colonne.
- Peut contenir
NULL(contrairement à une clé primaire).
Clé artificielle (Surrogate Key)
- Une clé générée artificiellement (souvent un id auto-incrémenté).
- N'a aucune signification métier.
- Très utilisée car simple, efficace et stable.
Clé naturelle (Natural Key)
- Issue de données du monde réel (ex. : numéro AVS, numéro de passeport).
- Avantage : elle a du sens pour l'utilisateur.
- Inconvénients :
- Elle peut changer.
- Elle peut devenir non unique.
- Elle peut être longue → impact performance.
Contraintes d'intégrité des données
Les contraintes garantissent la cohérence, l'exactitude et la fiabilité des données.
Contrainte d'intégrité d'entité
- Assure que chaque table possède une clé primaire unique.
- Interdit les valeurs `NULL dans une clé primaire.
Contraintes de domaine
Définissent quelles valeurs sont autorisées dans une colonne :
- type (
INT,VARCHAR,DATE, …) - longueur (
VARCHAR(255)) - format (
CHECK, regex SQL) - ensembles restreints (
ENUM)
Elles empêchent les données incorrectes ou incohérentes.
Contrainte d'intégrité référentielle
- Garantit la cohérence entre les tables liées par des clés étrangères.
- Empêche par exemple :
- De supprimer un client qui possède encore des commandes
- D'insérer dans la colonne
order.customer_idune valeur qui n'existe pas danscustomer.id.
Souvent associée à des actions :
ON DELETE CASCADEON DELETE RESTRICTON UPDATE CASCADE- …
Normalisation
La normalisation est un processus de conception visant à organiser les données dans une base relationnelle afin de :
- Réduire la redondance
- Eliminer les anomalies de mise à jour
- Garantir l'intégrité des données
- Améliorer la cohérence du modèle
Elle consiste à structurer les tables et leurs relations selon plusieurs niveaux appelés formes normales (NF).
Première Forme Normale (1NF)
Une table est en 1NF si :
- Chaque colonne contient uniquement des valeurs atomiques : aucune liste, aucun groupe de valeurs dans une même cellule.
- Chaque ligne est unique : souvent garanti par l'utilisation d'une clé primaire.
Exemple : Table non conforme à la 1NF
Supposons que nous ayons une table Commande qui enregistre les commandes des clients, où chaque commande peut inclure plusieurs produits.
| ID Client | Nom Client | Produits |
|---|---|---|
| 101 | Alice | Pommes, Bananes |
| 102 | Bob | Lait, Pain |
| 101 | Alice | Pommes, Bananes |
- La colonne
Produitsn'est pas atomique → contient plusieurs valeurs. - Les lignes ne sont pas uniques → même client avec mêmes produits répétés (un client a fait plusieurs fois la même commande de produits).
Transformation vers la 1NF
Pour respecter la 1NF :
- On sépare chaque produit en une ligne distincte.
- On introduit un
ID Commandepermettant d'identifier les commandes indépendamment du client.
| ID Commande | ID Client | Nom Client | Produit |
|---|---|---|---|
| 1 | 101 | Alice | Pommes |
| 1 | 101 | Alice | Bananes |
| 2 | 102 | Bob | Lait |
| 2 | 102 | Bob | Pain |
| 3 | 101 | Alice | Pommes |
| 3 | 101 | Alice | Bananes |
Résultat
✔ Chaque cellule contient maintenant une valeur simple.
✔ Chaque ligne est identifiable.
Clé primaire composite
Dans cette nouvelle table, il est possible d'utiliser une clé primaire composite : (ID Commande, Produit).
La combinaison d'un identifiant de commande unique et du nom du produit permet de garantir l'unicité de chaque ligne.
Ainsi, même si un client commande plusieurs fois les mêmes produits, les enregistrements restent correctement distingués grâce à ID Commande.
Deuxième Forme Normale (2NF)
Une table est en 2NF si :
- Elle est déjà en 1NF.
- Toutes les colonnes non-clé dépendent entièrement de la clé primaire.
Cela signifie :
- S'il existe une clé primaire composite, alors aucune colonne non-clé ne doit dépendre seulement d'une partie de cette clé.
- Une colonne non-clé doit dépendre de toute la clé, pas uniquement d'un morceau de la clé.
Exemple : Dépendance partielle
Dans la table issue de la 1NF :
| ID Commande | ID Client | Nom Client | Produit |
|---|---|---|---|
La clé primaire était : (ID Commande, Produit).
Mais :
ID Clientdépend uniquement deID CommandeNom Clientdépend uniquement deID Commande
Connaître seulement l'ID Commande permet de déterminer le client, sans avoir besoin du produit.
Cela viole la 2NF : Les colonnes non-clé ne dépendent pas entièrement de la clé primaire composite.
Transformation pour respecter la 2NF
Pour supprimer cette dépendance partielle, on scinde la table en deux tables distinctes.
-
Table
Commande: Contient les informations propres à la commande et au client.- Clé primaire :
ID Commande
ID Commande ID Client Nom Client 1 101 Alice 2 102 Bob 3 101 Alice - Clé primaire :
-
Table
Détail: Contient les produits associés à chaque commande.- Clé primaire composite : (
ID Commande,Produit)
ID Commande Produit 1 Pommes 1 Bananes 2 Lait 2 Pain 3 Pommes 3 Bananes - Clé primaire composite : (
Résultat
✔ Plus aucune dépendance partielle
✔ Toutes les colonnes non-clé dépendent entièrement de leur clé primaire
✔ La base est maintenant conforme à la 2ème Forme Normale
Troisième Forme Normale (3NF)
Une table est en 3NF si :
- Elle est déjà en 2NF.
- Il n'existe aucune dépendance transitive.
Cela signifie :
- Une colonne non-clé ne doit pas dépendre d'une autre colonne non-clé.
- Toutes les colonnes non-clé doivent dépendre uniquement de la clé primaire, et directement.
Exemple : Dépendance transitive
Dans la table Commande issue de la 2NF :
| ID Commande | ID Client | Nom Client |
|---|---|---|
- La clé primaire est :
ID Commande Nom Clientdépend deID ClientID Clientdépend deID Commande
Donc Nom Client dépend de ID Commande via ID Client : C'est une dépendance transitive.
Cela viole la 3NF.
Transformation pour respecter la 3NF
Pour supprimer la dépendance transitive, on sépare les données du client dans une table indépendante.
-
Table
Commande: Contient uniquement les informations propres à la commande.- Clé primaire :
ID Commande
ID Commande ID Client 1 101 2 102 3 101 - Clé primaire :
-
Table
Client: Contient les informations relatives au client.- Clé primaire :
ID Client
ID Client Nom Client 101 Alice 102 Bob - Clé primaire :
-
Table
Détail: Liste les produits associés à chaque commande.- Clé primaire composite : (
ID Commande,Produit)
ID Commande Produit 1 Pommes 1 Bananes 2 Lait 2 Pain 3 Pommes 3 Bananes - Clé primaire composite : (
Résultat
✔ Plus de dépendances transitives
✔ Chaque table dépend uniquement de sa clé primaire
✔ La structure respecte pleinement la 3ème Forme Normale
Note
Il existe d'autres formes normales (BCNF, 4NF, 5NF), non abordées dans ce cours.
La normalisation doit être adaptée aux besoins du projet :
- Trop normaliser augmente les jointures et peut nuire aux performances
- Trop peu normaliser entraîne des données redondantes et difficiles à maintenir
Cardinalité
La cardinalité décrit la manière dont les enregistrements de deux tables sont associés entre eux. Elle indique combien d'occurrences d'une entité peuvent être liées à combien d'occurrences d'une autre entité. C'est un concept fondamental dans la modélisation relationnelle.
Cardinalité Un-à-Un (1:1)
Chaque enregistrement d'une table est associé à au plus un enregistrement dans une autre table, et inversement.
Exemple : Un employé possède un seul badge d'accès, et chaque badge est attribué à un seul employé.
Table : Employé
- Clé primaire :
ID Employé
| ID Employé | Nom | Poste |
|---|---|---|
| 1 | Alice Dupont | Développeuse |
| 2 | Bob Martin | Analyste |
| 3 | Claire Lune | Responsable RH |
Table : Badge
- Clé primaire :
ID Badge - Clé étrangère :
ID Employé
| ID Badge | ID Employé | Code d'Accès |
|---|---|---|
| A100 | 1 | 12345 |
| A101 | 2 | 23456 |
| A102 | 3 | 34567 |

Cardinalité Un-à-Plusieurs (1:N)
Un enregistrement de la première table peut être lié à plusieurs enregistrements de la seconde table, mais la seconde table ne peut être liée qu'à un seul enregistrement de la première.
Exemple : Une catégorie contient plusieurs livres, mais chaque livre appartient à une seule catégorie.
Table : Catégorie
- Clé primaire :
ID Catégorie
| ID Catégorie | Nom Catégorie |
|---|---|
| 1 | Littérature |
| 2 | Science-Fiction |
| 3 | Histoire |
Table : Livre
- Clé primaire :
ID Livre - Clé étrangère :
ID Catégorie
| ID Livre | Titre | ID Catégorie |
|---|---|---|
| A1 | Les Misérables | 1 |
| A2 | Dune | 2 |
| A3 | Fondation | 2 |
| A4 | Guerre et Paix | 1 |
| A5 | Sapiens | 3 |

Cardinalité Plusieurs-à-Plusieurs (N:N)
Un enregistrement dans une table peut être associé à plusieurs enregistrements de l'autre table, et réciproquement.
Dans une base relationnelle, on implémente ce type de relation via une table d'association.
Exemple : Un étudiant peut s'inscrire à plusieurs cours, et chaque cours peut accueillir plusieurs étudiants.
Table : Etudiant
- Clé primaire :
ID Etudiant
| ID Etudiant | Nom Etudiant |
|---|---|
| 1001 | Alice Dupont |
| 1002 | Bob Martin |
| 1003 | Claire Lune |
Table : Cours
- Clé primaire :
ID Cours
| ID Cours | Nom Cours |
|---|---|
| C101 | Mathématiques |
| C102 | Littérature |
| C103 | Physique |
Table d'association : Inscription
- Clé primaire composite : (
ID Etudiant,ID Cours) - Clé étrangère :
ID EtudiantetID Cours
| ID Etudiant | ID Cours |
|---|---|
| 1001 | C101 |
| 1001 | C102 |
| 1002 | C102 |
| 1003 | C101 |
| 1003 | C103 |

Cardinalité obligatoire vs optionnelle
La cardinalité précise également si la relation est obligatoire ou facultative.
-
Exemple 1 - Relation obligatoire (1:N) :
Une commande doit obligatoirement être liée à un client :️ Une commande ne peut pas exister sans client.
-
Exemple 2 - Relation optionnelle (1:N) :
Une commande peut être liée à une promotion… mais ce n'est pas obligatoire :️ Certaines commandes ont une promotion, d'autres non.
Exemple
Considérons la table suivante regroupant des informations sur des employés, leurs compétences et les projets auxquels ils participent :
Table : Employé et Projet (non normalisée)
| Nom | Département | Compétences | ID Projet | Nom Projet |
|---|---|---|---|---|
| Alice Dupont | Informatique | Java, Python | P1 | Enterprise CRM |
| Martin Arnaud | Marketing | Marketing, Vente | P2 | Company website |
| Alice Dupont | Informatique | Web, Python | P3 | Company website |
| Elodie Thomas | Finance | Comptabilité, Excel | P2 | Company website |
| José Lopes Silva | Informatique | C++, Java | P1 | Enterprise CRM |
Cette table présente plusieurs problèmes typiques d'un mauvais modèle relationnel, ainsi que plusieurs anomalies (mise à jour, insertion, suppression).
Problèmes
-
Comment trier les employés par nom de famille ?
Les noms ne sont pas séparés en prénom et nom → ambiguïté.
-
Y a-t-il une ou deux Alice Dupont dans l'entreprise ?
Rien ne distingue les identités (absence d'ID).
-
Comment obtenir la liste des compétences uniques de l'entreprise ?
Elles sont stockées sous forme de listes de texte, rendant impossible une recherche fiable.
-
Redondance massive des données : les projets sont répétés, les compétences aussi.
Anomalies
-
Anomalies de mise à jour
-
Redondance des projets
Le nom du projet "Company website" apparaît plusieurs fois.
Si le nom change, il faut le modifier dans plusieurs lignes → risque d'incohérences.
-
Incohérence dans les compétences
Alice Dupont a deux listes différentes de compétences selon la ligne.
Une mise à jour correcte est impossible.
-
-
Anomalies d'insertion
- Impossible d'ajouter :
- Un nouvel employé sans projet → champ obligatoire de fait
- Un nouveau projet sans employé → dépendance artificielle
- Un employé sans compétences (nouvelle embauche)
- Impossible d'ajouter :
-
Anomalies de suppression
-
Supprimer une ligne peut entraîner une perte d'informations.
Par exemple, si José Lopes Silva quitte l'entreprise : son projet P1 disparaît partiellement de la table.
-
Version corrigée (normalisation)
Pour corriger ces anomalies, on sépare les données en plusieurs tables cohérentes et normalisées.
Table : Employé
- Clé primaire :
ID Employé
| ID Employé | Prénom | Nom | Département |
|---|---|---|---|
| 1 | Alice | Dupont | Informatique |
| 2 | Martin | Arnaud | Marketing |
| 3 | Elodie | Thomas | Finance |
| 4 | José | Lopes Silva | Informatique |
Table : Projet
- Clé primaire :
ID Projet
| ID Projet | Nom Projet |
|---|---|
| P1 | Enterprise CRM |
| P2 | Company website |
| P3 | Company website |
Table : Compétence
- Clé primaire :
ID Compétence
| ID Compétence | Nom Compétence |
|---|---|
| 1 | Java |
| 2 | Python |
| 3 | Marketing |
| 4 | Vente |
| 5 | Web |
| 6 | Comptabilité |
| 7 | Excel |
| 8 | C++ |
Table d'association : Employé - Compétence
- Clé primaire composite : (
ID Employé,ID Compétence) - Clé étrangère :
ID EmployéetID Compétence
| ID Employé | ID Compétence |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 1 | 5 |
| 2 | 3 |
| 2 | 4 |
| 3 | 6 |
| 3 | 7 |
| 4 | 1 |
| 4 | 8 |
Table d'association : Employé - Projet
- Clé primaire composite : (
ID Employé,ID Projet) - Clé étrangère :
ID EmployéetID Projet
| ID Employé | ID Projet |
|---|---|
| 1 | P1 |
| 1 | P3 |
| 2 | P2 |
| 3 | P2 |
| 4 | P1 |
