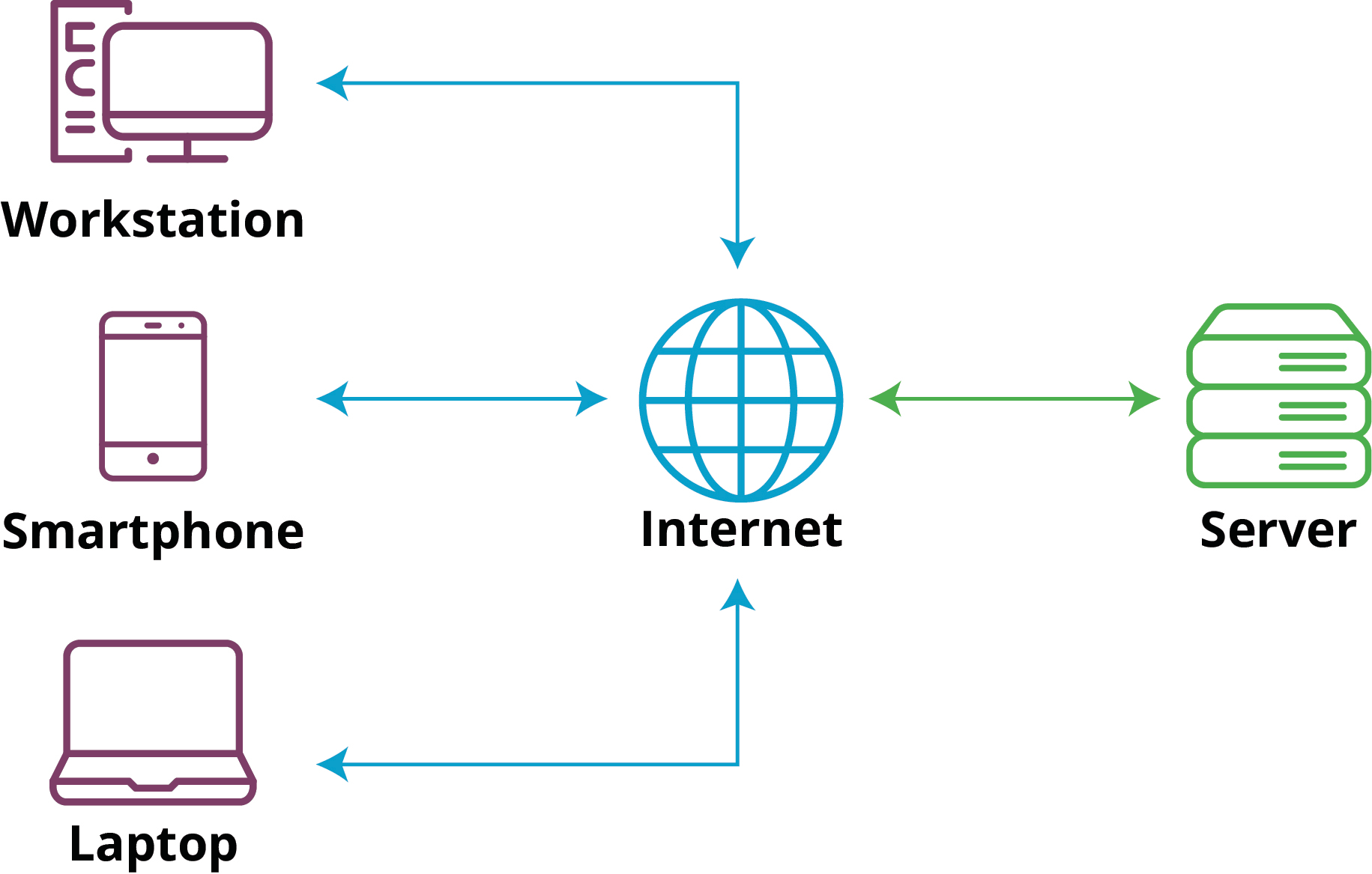
Client - Serveur
L'architecture client-serveur est un modèle fondamental en informatique qui sépare un système en deux entités principales : les clients (qui consomment des services) et les serveurs (qui fournissent ces services).

{kind=link}
Clients
- Dispositifs ou applications qui demandent des services ou des ressources à un serveur.
- Peuvent être des ordinateurs personnels, smartphones, tablettes, ou des logiciels spécialisés.
- Fonction : envoyer des requêtes au serveur pour obtenir des informations ou déclencher des actions.
Serveurs
- Systèmes informatiques conçus pour fournir des services, des données ou des ressources aux clients.
- Configurés pour écouter les requêtes entrantes et y répondre.
- Exemples de serveurs :
- Web
- Messagerie
- Bases de données
- Fichiers
- Généralement plus puissants et robustes que les clients, capables de gérer de nombreuses connexions simultanées.
Communication
- L'interaction entre clients et serveurs se fait via des protocoles de communication.
- Exemples :
- HTTP/HTTPS → web
- SMTP, IMAP, POP3 → messagerie
- SQL → bases de données
- FTP, SMB → fichiers
- Les clients envoient des requêtes, que le serveur traite avant de renvoyer une réponse appropriée.
Répartition des responsabilités
- Clients → interface utilisateur, affichage et présentation des données.
- Serveurs → logique métier, stockage des données, opérations de traitement.
- Cette séparation facilite la spécialisation et l'efficacité du système.
Avantages
- Scalabilité → possibilité d'ajouter des clients ou serveurs selon la charge.
- Centralisation des données → simplifie la gestion et la sauvegarde.
- Maintenance facilitée → les mises à jour effectuées sur le serveur profitent à tous les clients.
- Sécurité accrue → le serveur contrôle les accès et protège les ressources.
Inconvénients
- Dépendance au serveur → les clients ne fonctionnent généralement pas si le serveur est indisponible.
- Latence → les temps de réponse varient selon la charge et la qualité du réseau.
- Complexité → nécessite une gestion rigoureuse des interactions et de la sécurité.
Serveur web
Un serveur web est un logiciel ou un système informatique chargé de traiter les requêtes provenant des clients (navigateurs web, applications) et d'y répondre en fournissant des pages, des fichiers ou des services.
CERN httpd
Le CERN httpd fut le premier serveur HTTP, créé en 1990 par Tim Berners-Lee au CERN.
Son but : permettre aux chercheurs de partager facilement des informations sur Internet via les premières versions du protocole HTTP et du langage HTML.
Dans un réseau d'entreprise, un serveur web est généralement placé dans une DMZ (zone démilitarisée) afin de sécuriser les échanges entre clients externes et ressources internes.

{kind=link}
Note
Une DMZ (zone démilitarisée) est une zone de réseau intermédiaire et partiellement sécurisée, placée entre :
- un réseau interne sécurisé (réseau local de l'entreprise),
- et un réseau externe non sécurisé (comme Internet).
Son rôle est d'héberger des serveurs ou services qui doivent être accessibles depuis Internet, tout en limitant les risques pour le réseau interne.
Exemples de serveurs placés en DMZ :
- Serveur web
- Serveur de messagerie
- Serveur de fichiers
- Serveur DNS
- …
Parts de marché

HostAdvice / Global Web Hosting Market Share - September 2025


Client web
Un client web, dans le contexte d'Internet, est un logiciel ou une application qui permet aux utilisateurs d'accéder et d'interagir avec des ressources en ligne : sites web, fichiers, services et contenus divers.
Le type le plus courant de client web est le navigateur (browser).
Evolution des navigateurs web
Années 1990 - Les débuts
- 1990 : Tim Berners-Lee crée le premier navigateur web, WorldWideWeb (renommé plus tard Nexus), fonctionnant sur les machines NeXT.
- 1993 : sortie de Mosaic, développé à l'Université de l'Illinois. Premier navigateur grand public, il popularise le web.
- 1994 : lancement de Netscape Navigator par Netscape Communications. Son interface conviviale et ses fonctionnalités avancées en font un succès immédiat.
La « guerre des navigateurs » (milieu des années 1990)
- Concurrence féroce entre Netscape Navigator et Microsoft Internet Explorer (IE).
- Microsoft intègre IE à Windows, lui donnant un avantage décisif.
Années 2000 - L'ère d'Internet Explorer
- Internet Explorer domine le marché avec plus de 90% de parts à son apogée.
2004 - L'émergence de Firefox
- Lancement de Mozilla Firefox, navigateur open source.
- Succès grâce à sa sécurité, sa rapidité et ses options de personnalisation.
- Arrivée d'autres acteurs : Opera, Safari (Apple), et surtout Google Chrome.
2008 - L'arrivée de Google Chrome
- Chrome se distingue par son architecture rapide, son interface minimaliste et sa stabilité.
- Devenu rapidement l'un des navigateurs les plus populaires au monde.
2010 - Le déclin d'Internet Explorer
- IE perd progressivement sa domination au profit de Chrome, Firefox et Safari.
- Microsoft abandonne IE pour développer Microsoft Edge.
L'évolution des standards web
- Les navigateurs modernes s'alignent sur les standards ouverts : HTML5, CSS3, JavaScript.
- Cela améliore la compatibilité et la richesse des sites web.
La navigation mobile
- Les navigateurs mobiles deviennent incontournables avec l'essor des smartphones.
- Safari (iOS) et Chrome (Android) dominent sur mobile.
Tendances actuelles

Composants d'un navigateur web
Un navigateur web est un logiciel complexe qui combine plusieurs composants afin de permettre aux utilisateurs d'accéder aux ressources en ligne et de naviguer sur le web.
Voici les principaux éléments d'un navigateur typique :
- Interface utilisateur (UI)
- Partie visible avec laquelle l'utilisateur interagit.
- Comprend : la barre d'adresse (saisie des URL), les boutons de navigation (retour, avance, actualiser), la gestion des onglets, les favoris, ainsi que divers menus et barres d'outils.
- Moteur de rendu (Rendering Engine)
- Coeur du navigateur : il interprète le code source des pages (HTML, CSS, JavaScript) pour afficher le contenu sous une forme compréhensible.
- Exemples : Blink (Chrome, Edge), WebKit (Safari), Gecko (Firefox).
- Moteur JavaScript
- Exécute le code JavaScript inclus dans les pages web.
- Indispensable pour l'interactivité (animations, formulaires dynamiques, applications web).
- Exemples : V8 (Chrome, Edge), SpiderMonkey (Firefox), JavaScriptCore (Safari).
- Moteur CSS
- Spécialisé dans l'interprétation des feuilles de style (CSS).
- Gère l'apparence visuelle et la mise en page (couleurs, polices, positionnement).
- Travaille de concert avec le moteur de rendu pour assurer une présentation correcte et cohérente.
Moteurs de rendu HTML
Les moteurs de rendu (ou rendering engines) sont au coeur des navigateurs web. Ils ont pour rôle d'interpréter le code HTML, CSS et JavaScript afin d'afficher correctement les pages web à l'écran.
Moteurs actuels
- WebKit (Apple, dérivé de KHTML)
- Utilisé par Safari (macOS, iOS).
- Premier moteur moderne à avoir mis l'accent sur la rapidité et la compatibilité avec les standards web.
- Blink (Google, dérivé de WebKit)
- Utilisé par Chrome, Chromium, Edge (versions récentes), Opera et Brave.
- Aujourd'hui le moteur le plus répandu, dominant le marché grâce à Chrome.
- Gecko (Mozilla)
- Utilisé par Firefox.
- Moteur indépendant, fortement axé sur l'interopérabilité et la conformité aux standards.
Anciens moteurs (désormais obsolètes)
- EdgeHTML (Microsoft, dérivé de Trident)
- Utilisé par les anciennes versions de Microsoft Edge (avant la migration vers Chromium/Blink en 2020).
- Trident (Microsoft)
- Utilisé par Internet Explorer.
- Longtemps dominant dans les années 2000, mais critiqué pour son manque de compatibilité avec les standards.
- Presto (Opera Software)
- Utilisé par les anciennes versions d'Opera.
- Remplacé par Blink en 2013.
Bots
Les bots sont des programmes informatiques conçus pour effectuer des tâches automatisées sur Internet.
Ils sont considérés comme des clients web puisqu'ils accèdent aux ressources en ligne, mais contrairement aux navigateurs utilisés par des humains, ils agissent sans intervention directe.
Exemples de bots courants
- Moteurs de recherche : les crawlers de Google, Bing ou Yahoo explorent et indexent les pages web.
- Chatbots : utilisent l'IA pour converser avec les utilisateurs (service client, assistants virtuels).
- Web scrapers : extraient des données (prix, avis, actualités) pour analyse.
- Bots de réseaux sociaux : automatisent des publications, des réponses ou de la collecte de données.
- Bots de trading : exécutent automatiquement des transactions financières selon des algorithmes prédéfinis.
- Bots de jeux : automatisent des actions répétitives ou non autorisées dans les jeux en ligne.
- Bots de surveillance : surveillent des sites, forums ou applications pour détecter des changements ou tendances.
- Bots malveillants : explorent des vulnérabilités, diffusent du spam ou mènent des attaques automatisées.
Les bots peuvent donc être bénéfiques (indexation, automatisation utile) ou nuisibles (spam, piratage, fraude), selon leur usage et leur conception.