Encodage de caractères
L'encodage de caractères est le processus qui consiste à représenter des caractères, des symboles ou des textes sous forme de nombres binaires, afin qu'ils puissent être stockés, transmis et interprétés par les ordinateurs.
Autrement dit, c'est la traduction du langage humain en langage machine.
L'objectif est de permettre à des systèmes différents de lire, afficher et échanger du texte de manière cohérente.
Premiers systèmes d'encodage
Avant l'informatique, plusieurs systèmes ont permis de convertir des messages en signaux codés pour faciliter leur transmission à distance.
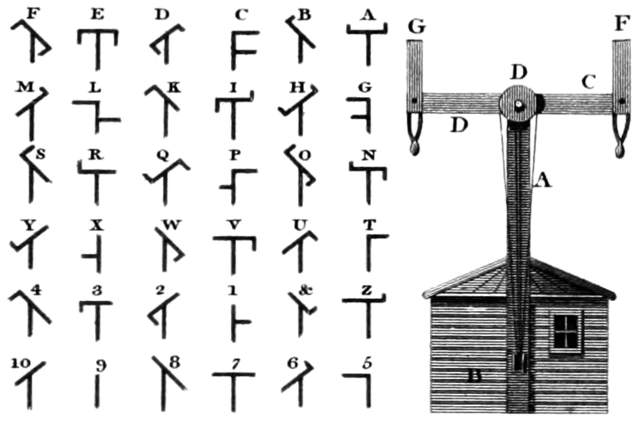
Télégraphe Chappe (1794)
Inventé par les frères Chappe, ce système de communication optique utilisait des bras mécaniques montés sur des tours.
Chaque position correspondait à une lettre, un chiffre ou un mot.
Les messages pouvaient être relayés de tour en tour, permettant de communiquer sur plusieurs centaines de kilomètres.

{kind=link}
Code Morse international (1838)
Créé par Samuel Morse, ce code représente chaque lettre ou chiffre par une combinaison de points et de tirets.
Il a permis les premières transmissions électriques rapides via le télégraphe, avant d'être utilisé dans la radio et la marine.

{kind=link}
Code international des signaux (1855)
En navigation, ce système utilise des drapeaux colorés pour représenter des lettres et des messages standardisés.
Il permet aux navires de communiquer indépendamment de la langue parlée, notamment pour signaler des situations d'urgence.

{kind=link}
ASCII
L'ASCII (American Standard Code for Information Interchange), publié en 1963, est le premier standard informatique majeur pour représenter du texte.
- Chaque caractère (lettre, chiffre ou symbole) reçoit une valeur numérique entre 0 et 127.
- Les caractères sont codés sur 7 bits, ce qui permet de représenter 128 caractères possibles.
- Il inclut aussi des caractères de contrôle (comme \n pour retour à la ligne ou \t pour tabulation).

{kind=link}
ASCII étendu
Avec l'arrivée des ordinateurs multilingues dans les années 1980, une version à 8 bits a été introduite.
Elle permet d'ajouter des lettres accentuées, symboles et caractères régionaux.
- Exemples : ISO 8859-1 pour l'Europe de l'Ouest, ISO 8859-5 pour le cyrillique.
- Ces extensions varient selon les régions, d'où la nécessité de gérer des "code pages".
Note
Une code page est une table de correspondance utilisée par les systèmes d'exploitation et les logiciels pour relier les valeurs numériques (codes) aux caractères affichés.
Chaque code page définit son propre jeu de caractères, ce qui permet d'adapter l'affichage du texte à une langue ou une région donnée.
ISO 8859-1 (Latin alphabet No. 1)

ISO 8859-5 (Latin/Cyrillic alphabet)

Problématique des code pages
L'inconvénient majeur des code pages est qu'elles ne sont pas universelles : chaque région ou langue possède sa propre table d'encodage.
Ainsi, le même nombre binaire peut représenter des caractères différents selon la code page utilisée.
Cela entraînait des problèmes d'affichage lorsqu'un texte était lu avec un encodage incorrect, phénomène connu sous le nom de mojibake (文字化け, "caractères corrompus").
Exemple concret :
- Une page encodée en ISO 8859-1 s'affichera mal si le navigateur l'interprète comme ISO 8859-5 (cyrillique).
Encodage ISO 8859-1

Encodage ISO 8859-5

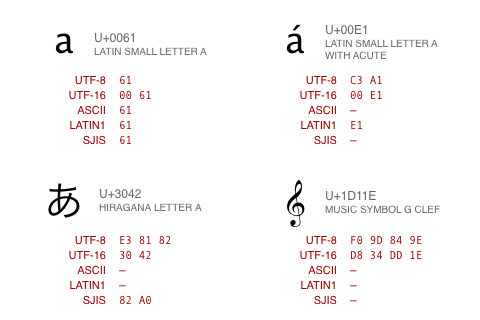
Caractères et encodage
Tous les caractères ne sont pas disponibles dans chaque code page, et un même caractère n'a pas forcément le même code d'une page à l'autre. Ce morcellement a rendu difficile la communication entre systèmes utilisant des langues différentes, d'où la création de la norme Unicode.

{kind=link}
Unicode
Pour résoudre ces problèmes, le consortium Unicode a publié en 1991 une norme universelle : chaque caractère de toutes les langues reçoit un identifiant unique, appelé code point.
Unicode vise à unifier tous les systèmes d'écriture, symboles, émojis et signes techniques dans une seule table mondiale.
Exemple :
- Lettre A → U+0041
- Emoji 😄 → U+1F604
UTF-8
UTF-8 (Unicode Transformation Format - 8 bits) est un format d'encodage pour les caractères Unicode. Créé en 1993, il permet de stocker chaque caractère avec 1 à 4 octets, selon sa complexité.
- Lettres ASCII : 1 octet (compatibilité rétroactive)
- Lettres accentuées : 2 octets
- Symboles et emojis : 3 à 4 octets

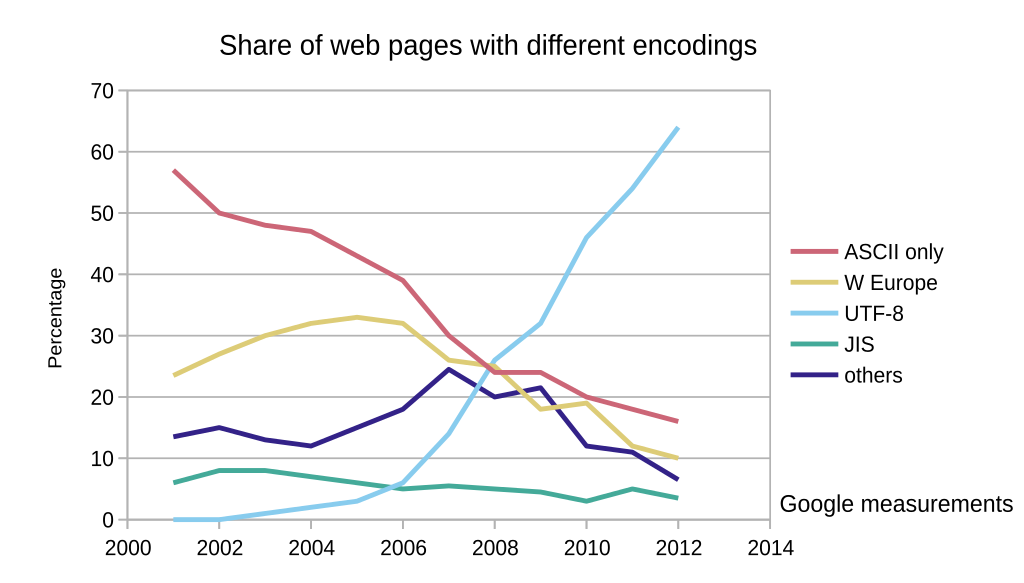
C'est aujourd'hui l'encodage standard du web (environ 99 % des sites).


{kind=link}
Unicode ≠ UTF-8
Unicode : norme définissant tous les caractères et leurs identifiants (code points).
UTF-8 : méthode concrète pour stocker ces identifiants sous forme binaire.
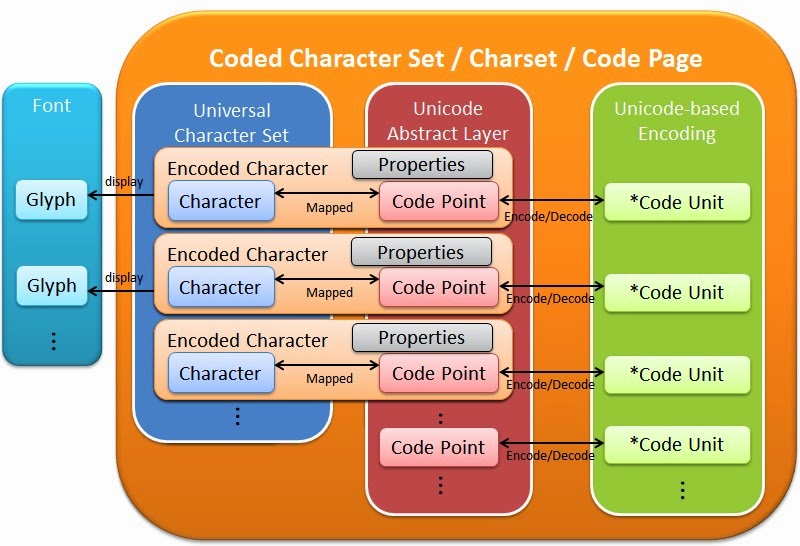
Terminologie essentielle
Character : Unité minimale de texte (glyphe).
Character set : Ensemble de caractères disponibles.
Coded character set : Ensemble où chaque caractère a un identifiant unique.
Code point : Identifiant numérique (U+XXXX).
Code unit : Séquence binaire représentant le caractère.
Encoding : Conversion des caractères en binaire pour stockage ou transmission.

Fonctionnement Unicode et affichage
Voici les principales étapes qui permettent à un simple code binaire d'être transformé en caractère visible à l'écran :
-
Bits en mémoire (Code binaire)
- Le texte est stocké sous forme de suites de bits (0 et 1).
- Par exemple, le caractère
aest enregistré comme la séquence binaire suivante01100001. - Ces bits représentent une unité de code (code unit) selon un encodage (ici UTF-8).
-
Décodage de l'encodage (UTF-8 → Unicode)
- Le système lit la séquence binaire selon les règles de l'encodage UTF-8.
- Il identifie qu'il s'agit d'un seul octet valide et le convertit en code point Unicode
U+0061. - Ce code point correspond à la lettre latine minuscule
adans la norme Unicode.
-
Correspondance avec un glyphe (mapping police de caractères)
- Le système d'exploitation ou le moteur de rendu (par ex. FreeType, DirectWrite, Core Text, etc.) recherche dans la police de caractères active le glyphe correspondant à
U+0061. - Un glyphe est la représentation graphique du caractère (sa forme visuelle).
- Le système d'exploitation ou le moteur de rendu (par ex. FreeType, DirectWrite, Core Text, etc.) recherche dans la police de caractères active le glyphe correspondant à
-
Chargement et rendu du glyphe
- Le moteur de rendu lit les données vectorielles ou bitmap du glyphe (formes, contours, proportions).
- Il applique éventuellement des réglages de lissage (antialiasing), crénelage (hinting) ou subpixel rendering pour améliorer la lisibilité à l'écran.
-
Affichage à l'écran (rasterisation)
- Le glyphe final est rendu en pixels par la carte graphique (GPU) ou le processeur.
- Le pixel buffer est ensuite envoyé à l'écran, où le caractère a apparaît sous la forme visible que l'on connait.

{kind=link}
Unicode aujourd'hui
Unicode 17.0 contient actuellement : 159'801 glyphes [septembre 2025]



Glyphes manquants


Si un caractère n'est pas affiché (souvent remplacé par un carré ou un '?'), c'est que la police utilisée ne contient pas le glyphe correspondant.
Vous devez posséder une police de caractères avec les glyphes !
